Agencia de Marketing Digital en España
SEO, diseño web, desarrollo, inteligencia artificial y PPC. Un equipo 100% senior con IA propia que convierte inversión en crecimiento medible.
Trabajan con nosotros


































Un equipo de seniors obsesionado con tu ROI
No somos una agencia más. Diseñamos estrategias de crecimiento digital donde cada acción—SEO, diseño, desarrollo, IA o publicidad—responde a un objetivo de negocio medible. Metodología propia, herramientas internas con IA y una transparencia radical que nos define.
Solo seniors
No hay juniors en nuestro equipo. Cada proyecto—ya sea SEO, web o IA—lo lleva un consultor con más de 10 años de experiencia en su área. 9 perfiles especializados que cubren cada ángulo del marketing digital.
Metodología NextLevel Agile
Sprints de 2 semanas con objetivos medibles para cada servicio. Transparencia total a través de Asana. Ves exactamente qué hacemos, cuándo y por qué—en SEO, desarrollo, diseño o PPC.
Tecnología propia
Clickeo AI para SEO y Firebuzz para landing pages PPC, scoring de enlaces con IA que analiza decenas de KPIs, tema propio de PrestaShop con +20 módulos custom. No usamos ChatGPT: desarrollamos nuestras propias herramientas.
Sin permanencia
Trabajamos por la calidad de nuestros resultados, no por obligación contractual. Aplica a todos nuestros servicios: si no entregamos valor, eres libre de irte.
No somos otra agencia.
Somos la opuesta.
Compara punto por punto. Cambia de vista para descubrir la diferencia.
Sprints de 2 semanas con entregables reales
Cada sprint cierra con resultados medibles. Sin resultados, te vas. Así de simple.
Contratos de 6–12 meses sin visibilidad
Atado por contrato sin saber qué pasa con tu inversión. Informes vagos cada trimestre.
Transparencia total en Asana — ves cada tarea
Cada hora de trabajo, cada decisión, visible en tiempo real. Cero cajas negras.
Informes mensuales PDF genéricos
Un PDF bonito que no explica nada. Sin acceso al trabajo real que se hace (o no).
Código a medida, theme propio, módulos custom
Cada línea de código construida para tu negocio. Rendimiento y SEO desde el primer commit.
Plantillas WordPress con 50 plugins
Template de 59 euros, plugins genéricos, la misma fórmula repetida para todos.
IA propia: Clickeo AI para contenido y análisis
Scoring de enlaces, automatización inteligente, contenido optimizado a medida con IA entrenada.
ChatGPT copy-paste sin supervisión
Herramientas gratuitas y cero desarrollo propio. Lo mismo que puede hacer cualquiera.
100% seniors, 0 juniors, 0 rotación
9 especialistas con +10 años de media. Tu equipo de siempre, sin cambios cada trimestre.
Juniors rotando cada trimestre
Un comercial vende, un junior ejecuta, y cada trimestre te cambian de cuenta.
¿Ves la diferencia? No es marketing. Es cómo trabajamos.
Trabaja con nosotrosTodo lo que necesitas para dominar el digital
14 servicios especializados organizados en 4 áreas. Un solo equipo. Un solo interlocutor. Cero fricción.
Posicionamiento orgánico con consultores seniors, metodología propia y tecnología de IA interna.
SEO
Estrategia SEO integral con consultores seniors y herramientas internas de IA.
Auditoría SEO
Radiografía completa: técnico, contenido, autoridad. Plan de acción con prioridades.
Consultoría SEO
Acompañamiento estratégico continuo. SEO integrado en tu negocio.
SEO Local
Domina Google Maps y las búsquedas de tu zona.
SEO PrestaShop
Especialistas ecommerce. +80 tiendas, hasta +1600% crecimiento.
Link Building
Autoridad con enlaces de calidad. +3M€ invertidos, +12K enlaces.
Migraciones SEO
Cambio de CMS, dominio o estructura sin perder tráfico.
Penalizaciones SEO
Diagnóstico y recuperación. 95% tasa de éxito.
Webs premium a medida que convierten: cada píxel con propósito, código limpio y rendimiento máximo.
Campañas de pago y analítica avanzada para escalar resultados de forma rentable.
Inteligencia artificial y contenido estratégico para empresas que quieren ir un paso por delante.
Tecnología propia que nos diferencia
Dos plataformas de IA desarrolladas internamente. Cero dependencia de herramientas genéricas.
Clickeo AI
clickeo.ai
Plataforma de IA para SEO. Genera, optimiza y escala contenido de forma autónoma.
- Generación de contenidos con IA
- Optimización de metas y títulos
- Detección de canibalizaciones
- Interlinking inteligente
- Indexación masiva y monitorización
Firebuzz
getfirebuzz.com
Plataforma de IA para PPC. Crea landings, testea y optimiza campañas automáticamente.
- Landing pages con IA
- A/B testing de páginas
- Analíticas en tiempo real
- Campañas multi-idioma
- Optimización automática de pujas
Un equipo que no encontrarás
en otra agencia
Nueve consultores sénior con más de una década de experiencia media. Cero juniors. Cero rotación. Solo gente que sabe exactamente lo que hace.
Conoce al equipo que trabajará en tu proyecto.
Habla con nosotrosMetodología NextLevel Agile
Transparencia total, iteración constante y un equipo que trabaja como extensión de tu empresa. No vendemos humo: vendemos sprints con resultados.
Roles especializados
Cada miembro tiene un rol claro y especializado. No generalistas, sino expertos que aportan conocimiento profundo a cada proyecto.
Sprints de 2 semanas
Organizamos el trabajo en ciclos cortos con objetivos medibles. Al final de cada sprint, ves resultados tangibles y decides los siguientes pasos.
Comunicación directa
Canal directo con tu equipo en Asana. Sin intermediarios, sin esperas. Reuniones semanales y acceso en tiempo real al estado de cada tarea.
Experiencia sectorial
Más de una década trabajando con sectores diversos. Conocemos qué funciona en cada industria porque ya lo hemos probado, medido y optimizado.
Estrategia a medida
Nada de plantillas. Cada estrategia se construye desde cero analizando tus objetivos, tu competencia y tu mercado. Porque tu negocio no es genérico.
Resultados que hablan por nosotros
Incremento medio de tráfico orgánico cualificado y posiciones en los primeros 12 meses
+520% leads · +280% ingresos · +12K enlaces adquiridos
Ver casos de éxito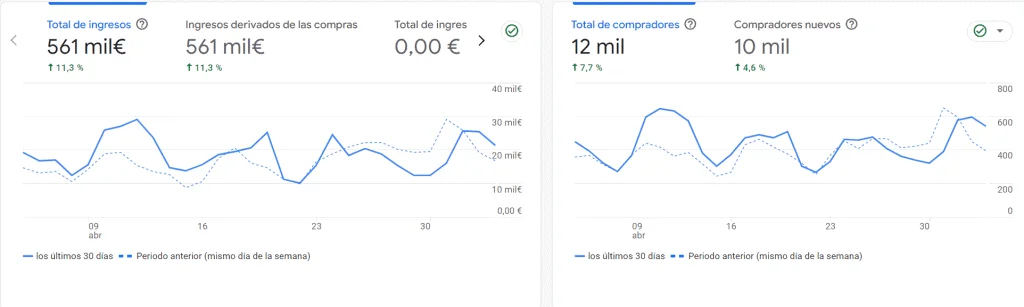
Lo que dicen nuestros clientes
"En 8 meses pasamos de 2.000 a 14.000 visitas orgánicas mensuales. El equipo de RoiLab identificó verticales que ni sabíamos que existían. El ROI del proyecto SEO superó x12 la inversión."
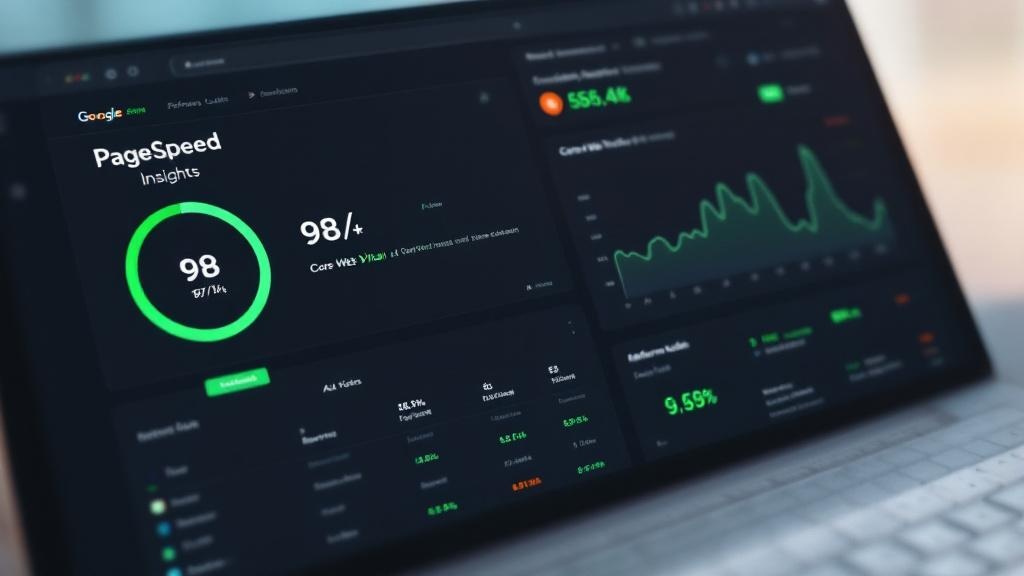
"Rediseñaron nuestra web y el PageSpeed pasó de 34 a 98. Las conversiones de formulario aumentaron un 180%. Lo mejor: el diseño transmite exactamente la confianza que necesitábamos."
"La auditoría SEO reveló que teníamos 340 URLs canibalizándose entre sí. Tras la reestructuración, triplicamos el tráfico orgánico en 5 meses. Brutal nivel de detalle."
"Llevaban nuestra cuenta de Google Ads 3 agencias antes. RoiLab redujo el CPC un 42% y aumentó las conversiones un 210%. El ROAS pasó de 2.1 a 5.8 en el primer trimestre."
"Desarrollaron nuestra plataforma SaaS desde cero con React y Node.js. Código impecable, documentación perfecta y entrega adelantada. 14 meses después, cero bugs críticos."
"La estrategia de contenidos nos posicionó como referentes del sector formación online. De 0 a 45 keywords en top 3 en menos de un año. El calendario editorial es una máquina."
"Migraron nuestra tienda PrestaShop sin perder una sola posición. El tráfico orgánico creció un 340% en 10 meses con la estrategia de verticales que diseñaron."
"El chatbot de IA que desarrollaron resuelve el 73% de las consultas sin intervención humana. Liberó a nuestro equipo de soporte para tareas de mayor valor. Increíble."
"SEO local impecable. Pasamos de no aparecer en Google Maps a dominar las 3 primeras posiciones en todas nuestras zonas. Las llamadas desde Google se triplicaron."
"La automatización con IA que implementaron redujo nuestro tiempo de procesamiento de pedidos un 65%. El modelo predictivo de demanda nos ahorra miles de euros al mes en stock."
"De 800 a 6.200 visitas orgánicas al mes. Cada artículo del blog que publican genera entre 200 y 500 visitas mensuales por sí solo. La inversión en contenidos se pagó sola en 4 meses."
"El link building estratégico con su scoring IA es otro nivel. Cada enlace viene con datos de tráfico real, relevancia temática y puntuación. Nuestra autoridad de dominio subió 18 puntos."
"Integración de Clickeo AI en nuestros procesos internos. Generamos informes que antes tardaban 3 horas en 12 minutos. La IA no sustituye a nuestro equipo, lo potencia."
"El diseño de la nueva web es espectacular y las ventas online se duplicaron. El equipo entendió perfectamente qué necesitaba nuestro sector: confianza, profesionalidad y velocidad."
"SEO local + Google Ads. En 3 meses llenamos las reservas de martes a jueves, que eran nuestros días flojos. El coste por reserva bajó de 12 euros a 3.40 euros."
"La consultoría SEO trimestral con RoiLab es la inversión más rentable que hacemos. El roadmap priorizado por impacto nos permite ejecutar con nuestro equipo interno con total claridad."
"Nos hicieron la auditoría más exhaustiva que hemos visto. 87 páginas de análisis real, no relleno. Cada acción priorizada con impacto estimado. Implementamos el 60% y el tráfico se multiplicó por 4."
"Los módulos PrestaShop propios de RoiLab transformaron nuestra tienda. El módulo de enlazado interno automático solo ya aumentó las páginas vistas por sesión un 45%."
"En 8 meses pasamos de 2.000 a 14.000 visitas orgánicas mensuales. El equipo de RoiLab identificó verticales que ni sabíamos que existían. El ROI del proyecto SEO superó x12 la inversión."
"Rediseñaron nuestra web y el PageSpeed pasó de 34 a 98. Las conversiones de formulario aumentaron un 180%. Lo mejor: el diseño transmite exactamente la confianza que necesitábamos."
"La auditoría SEO reveló que teníamos 340 URLs canibalizándose entre sí. Tras la reestructuración, triplicamos el tráfico orgánico en 5 meses. Brutal nivel de detalle."
"Llevaban nuestra cuenta de Google Ads 3 agencias antes. RoiLab redujo el CPC un 42% y aumentó las conversiones un 210%. El ROAS pasó de 2.1 a 5.8 en el primer trimestre."
"Desarrollaron nuestra plataforma SaaS desde cero con React y Node.js. Código impecable, documentación perfecta y entrega adelantada. 14 meses después, cero bugs críticos."
"La estrategia de contenidos nos posicionó como referentes del sector formación online. De 0 a 45 keywords en top 3 en menos de un año. El calendario editorial es una máquina."
"Migraron nuestra tienda PrestaShop sin perder una sola posición. El tráfico orgánico creció un 340% en 10 meses con la estrategia de verticales que diseñaron."
"El chatbot de IA que desarrollaron resuelve el 73% de las consultas sin intervención humana. Liberó a nuestro equipo de soporte para tareas de mayor valor. Increíble."
"SEO local impecable. Pasamos de no aparecer en Google Maps a dominar las 3 primeras posiciones en todas nuestras zonas. Las llamadas desde Google se triplicaron."
"La automatización con IA que implementaron redujo nuestro tiempo de procesamiento de pedidos un 65%. El modelo predictivo de demanda nos ahorra miles de euros al mes en stock."
"De 800 a 6.200 visitas orgánicas al mes. Cada artículo del blog que publican genera entre 200 y 500 visitas mensuales por sí solo. La inversión en contenidos se pagó sola en 4 meses."
"El link building estratégico con su scoring IA es otro nivel. Cada enlace viene con datos de tráfico real, relevancia temática y puntuación. Nuestra autoridad de dominio subió 18 puntos."
"Integración de Clickeo AI en nuestros procesos internos. Generamos informes que antes tardaban 3 horas en 12 minutos. La IA no sustituye a nuestro equipo, lo potencia."
"El diseño de la nueva web es espectacular y las ventas online se duplicaron. El equipo entendió perfectamente qué necesitaba nuestro sector: confianza, profesionalidad y velocidad."
"SEO local + Google Ads. En 3 meses llenamos las reservas de martes a jueves, que eran nuestros días flojos. El coste por reserva bajó de 12 euros a 3.40 euros."
"La consultoría SEO trimestral con RoiLab es la inversión más rentable que hacemos. El roadmap priorizado por impacto nos permite ejecutar con nuestro equipo interno con total claridad."
"Nos hicieron la auditoría más exhaustiva que hemos visto. 87 páginas de análisis real, no relleno. Cada acción priorizada con impacto estimado. Implementamos el 60% y el tráfico se multiplicó por 4."
"Los módulos PrestaShop propios de RoiLab transformaron nuestra tienda. El módulo de enlazado interno automático solo ya aumentó las páginas vistas por sesión un 45%."
"Necesitábamos una web que transmitiera innovación tecnológica. El resultado superó nuestras expectativas: 99 en PageSpeed, animaciones sutiles y una tasa de conversión del 4.2% en la landing."
"De 120 pedidos al mes a 480. La estrategia SEO para ecommerce de RoiLab identifica las categorías con mayor margen y las posiciona primero. Inteligente y rentable."
"El dashboard de Looker Studio que configuraron es increíble. Por primera vez vemos datos de negocio reales, no métricas de vanidad. La analítica web ahora influye en decisiones estratégicas."
"Google Ads gestionado por profesionales de verdad. El quality score medio de nuestras campañas pasó de 5 a 9. Eso se traduce en menos coste y más visibilidad. Resultados tangibles."
"Migramos de WooCommerce a PrestaShop con RoiLab. Cero pérdida de tráfico, mejora del 40% en velocidad de carga y las ventas orgánicas crecieron un 180% el primer semestre."
"El contenido que crean no es genérico. Cada artículo demuestra conocimiento real del sector salud y estética. Los topic clusters que diseñaron nos posicionaron para 120+ keywords."
"Desarrollaron nuestra app web con React y una API en Node.js que conecta con 5 portales inmobiliarios. Rendimiento excepcional y mantenimiento impecable desde hace 2 años."
"La penalización algorítmica nos había costado el 70% del tráfico. RoiLab diagnosticó el problema en 48 horas e implementó un plan de recuperación. En 4 meses estábamos por encima del nivel anterior."
"SEO local para 12 ubicaciones diferentes. Cada hotel domina su zona en Google Maps. Las reservas directas (sin intermediarios) crecieron un 85%. La comisión que nos ahorramos paga el servicio x3."
"La estrategia de link building con scoring IA nos dio enlaces de medios como El País, Expansión y Fashion Network. La autoridad del dominio se disparó y con ella las posiciones."
"Implementaron un sistema de IA que clasifica automáticamente los emails de clientes por urgencia y tipo. El tiempo de respuesta medio bajó de 4 horas a 22 minutos."
"Web nueva con diseño premium, SEO local configurado y campañas de Google Ads. Triple impacto: las citas online pasaron de 15 a 90 semanales en solo 2 meses."
"La web que nos diseñaron transmite exactamente lo que somos: ingeniería de alto nivel. Cada sección está pensada para nuestro cliente ideal B2B. Las solicitudes de presupuesto se triplicaron."
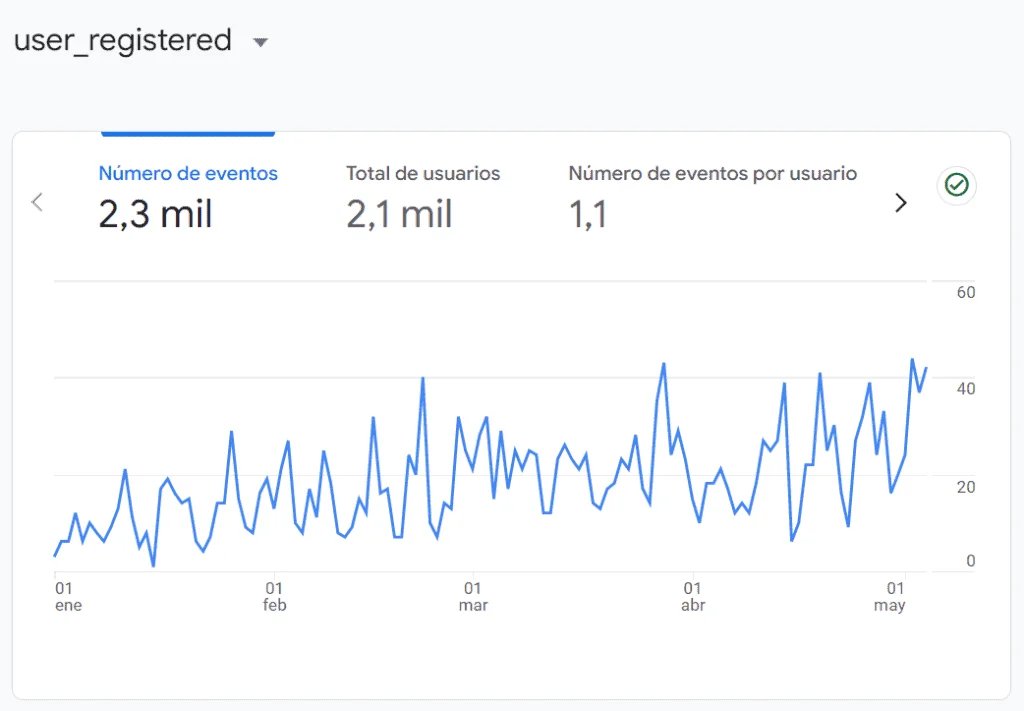
"El análisis de GA4 que implementaron nos reveló que el 40% de nuestros leads venían de contenido que ni sabíamos que funcionaba. Ahora tomamos decisiones con datos reales."
"PrestaShop SEO al más alto nivel. Pasamos de 3.200 visitas orgánicas a 28.000 en 12 meses. La estrategia de verticales por tipo de suplemento fue la clave del crecimiento."
"Posicionamiento local perfecto. Aparecemos primeros en "coworking Barcelona" y variantes. El 60% de nuestras altas nuevas vienen de búsquedas orgánicas. Sin pagar un euro en ads."
"RoiLab entiende el sector de las renovables mejor que muchas agencias especializadas. La auditoría técnica detectó problemas de indexación que llevaban 2 años sin resolverse."
"Necesitábamos una web que transmitiera innovación tecnológica. El resultado superó nuestras expectativas: 99 en PageSpeed, animaciones sutiles y una tasa de conversión del 4.2% en la landing."
"De 120 pedidos al mes a 480. La estrategia SEO para ecommerce de RoiLab identifica las categorías con mayor margen y las posiciona primero. Inteligente y rentable."
"El dashboard de Looker Studio que configuraron es increíble. Por primera vez vemos datos de negocio reales, no métricas de vanidad. La analítica web ahora influye en decisiones estratégicas."
"Google Ads gestionado por profesionales de verdad. El quality score medio de nuestras campañas pasó de 5 a 9. Eso se traduce en menos coste y más visibilidad. Resultados tangibles."
"Migramos de WooCommerce a PrestaShop con RoiLab. Cero pérdida de tráfico, mejora del 40% en velocidad de carga y las ventas orgánicas crecieron un 180% el primer semestre."
"El contenido que crean no es genérico. Cada artículo demuestra conocimiento real del sector salud y estética. Los topic clusters que diseñaron nos posicionaron para 120+ keywords."
"Desarrollaron nuestra app web con React y una API en Node.js que conecta con 5 portales inmobiliarios. Rendimiento excepcional y mantenimiento impecable desde hace 2 años."
"La penalización algorítmica nos había costado el 70% del tráfico. RoiLab diagnosticó el problema en 48 horas e implementó un plan de recuperación. En 4 meses estábamos por encima del nivel anterior."
"SEO local para 12 ubicaciones diferentes. Cada hotel domina su zona en Google Maps. Las reservas directas (sin intermediarios) crecieron un 85%. La comisión que nos ahorramos paga el servicio x3."
"La estrategia de link building con scoring IA nos dio enlaces de medios como El País, Expansión y Fashion Network. La autoridad del dominio se disparó y con ella las posiciones."
"Implementaron un sistema de IA que clasifica automáticamente los emails de clientes por urgencia y tipo. El tiempo de respuesta medio bajó de 4 horas a 22 minutos."
"Web nueva con diseño premium, SEO local configurado y campañas de Google Ads. Triple impacto: las citas online pasaron de 15 a 90 semanales en solo 2 meses."
"La web que nos diseñaron transmite exactamente lo que somos: ingeniería de alto nivel. Cada sección está pensada para nuestro cliente ideal B2B. Las solicitudes de presupuesto se triplicaron."
"El análisis de GA4 que implementaron nos reveló que el 40% de nuestros leads venían de contenido que ni sabíamos que funcionaba. Ahora tomamos decisiones con datos reales."
"PrestaShop SEO al más alto nivel. Pasamos de 3.200 visitas orgánicas a 28.000 en 12 meses. La estrategia de verticales por tipo de suplemento fue la clave del crecimiento."
"Posicionamiento local perfecto. Aparecemos primeros en "coworking Barcelona" y variantes. El 60% de nuestras altas nuevas vienen de búsquedas orgánicas. Sin pagar un euro en ads."
"RoiLab entiende el sector de las renovables mejor que muchas agencias especializadas. La auditoría técnica detectó problemas de indexación que llevaban 2 años sin resolverse."
Los números que nos respaldan
Recomienda.
Genera ingresos .
Cada cliente que nos refieras se convierte en una fuente de ingresos recurrente para ti. Sin techo, sin letra pequeña.
Ideal para consultores, freelancers y agencias complementarias.
Hablemos de tu proyecto
SEO, diseño web, desarrollo, IA o PPC: cuéntanos qué necesitas y un equipo senior lo hará realidad.